1. 需求
爬取到孙艺珍Instagram上的所有照片和视频。
2. 解决过程
阶段1
先打开网页,OBOB。
该页面初始时只显示12张照片,通过点击”更多“按钮,屏幕一直往下滚动,会显示更多,直到显示出所有的照片和视频。在此过程中,该网页并没有重新加载。所以新显示出来的照片和视频是通过Ajax技术从服务器获取到的。
之前理解的爬虫一直是找HTML文件中的某些内容,并且根据某些规则不停地更新需要请求的网页列表,这样就不断的有新的HTML文件。
针对现在这种情况。会有两种解决方案?一种是在代码中模拟屏幕滚动,将所有内容都显示出来后,爬下整个HTML,从中找到照片和视频的url(或者边滚动边查找);另一种是直接去找XHR(XmlHttpRequest对象),其中肯定存有照片和视频的url信息。
阶段2
通过Chrome调试工具查找请求url、图片和视频地址的存储模式。
先调出调试工具,再刷新一下页面。在Network下选中XHR,发现有些文件。
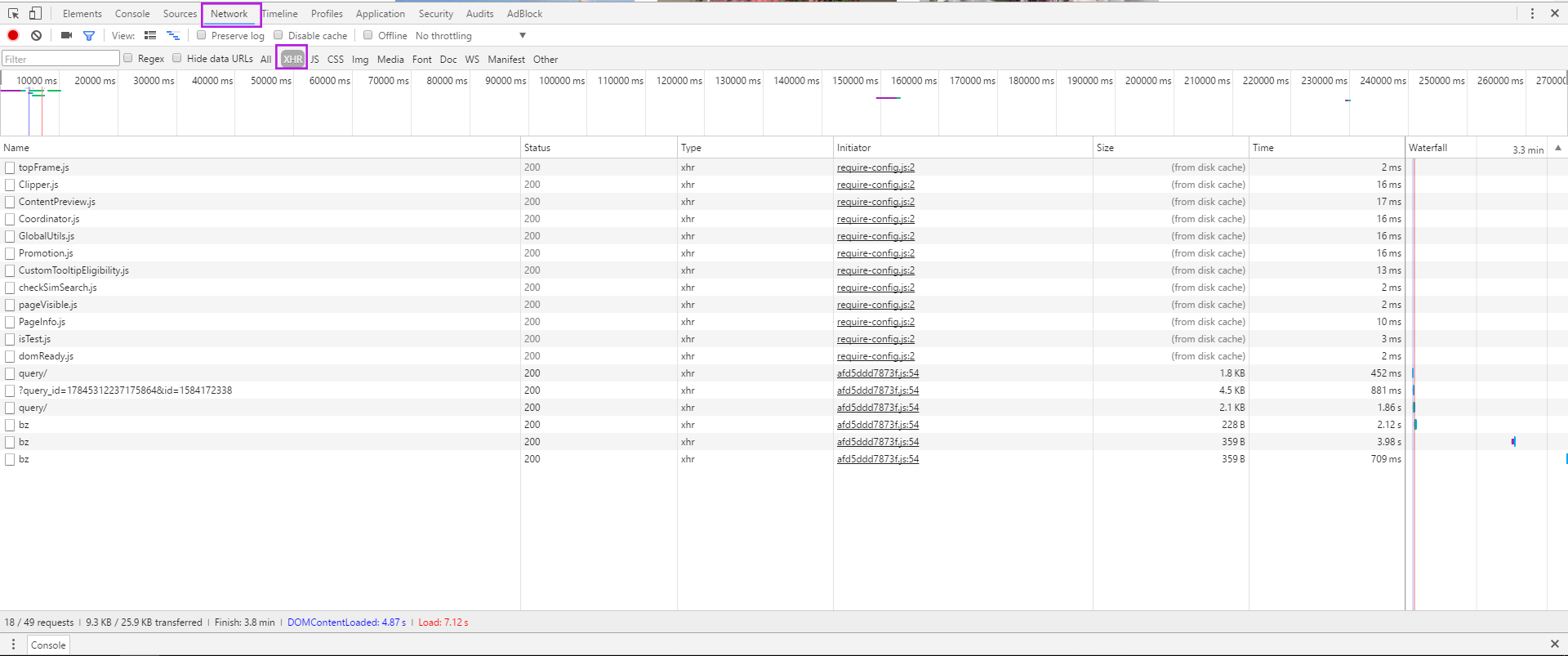
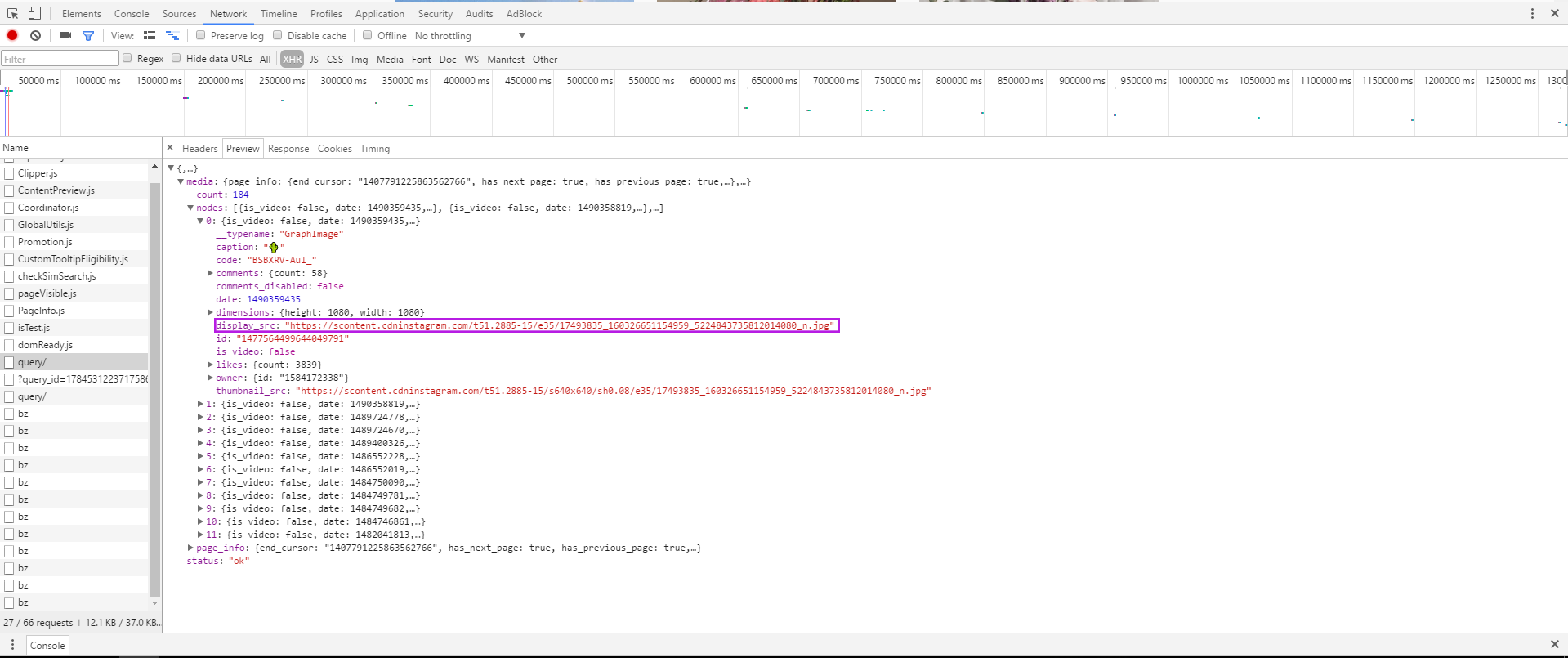
发现其中query文件中有所需的东西。它返回的响应是一段json文件,通过调试工具提供的Preview可以方便的找到12张照片的url在nodes的12个对象中。
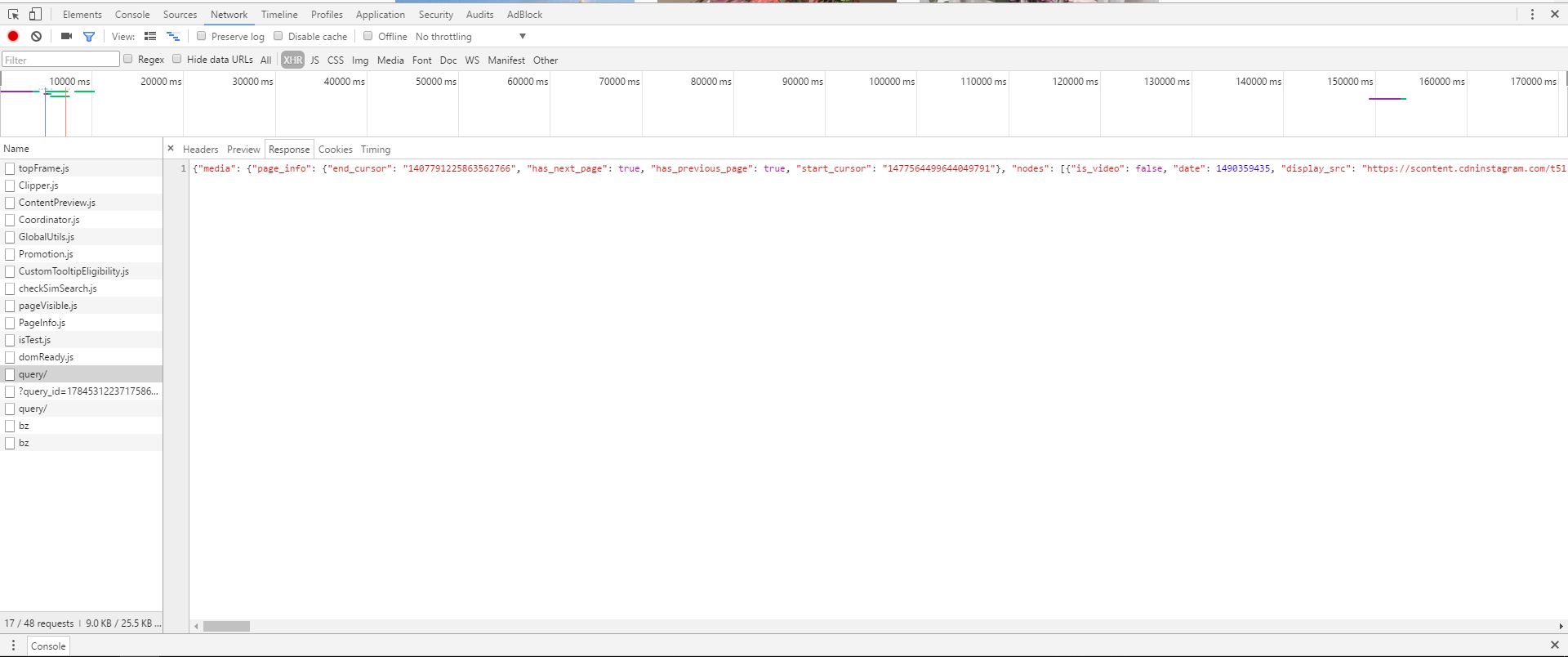
再仔细OB它的headers。调试工具帮忙将其分为了General、Response Headers、Request Headers和Form Data四个部分。从General中可以找到请求的url是h ttps://www.instagram.com/query/(h后空了个格,否则被解析成链接??),请求的方法是POST,由于需要翻个墙,所以Remote Address是127.0.0.1:1080(这块儿还不清楚为什么)。
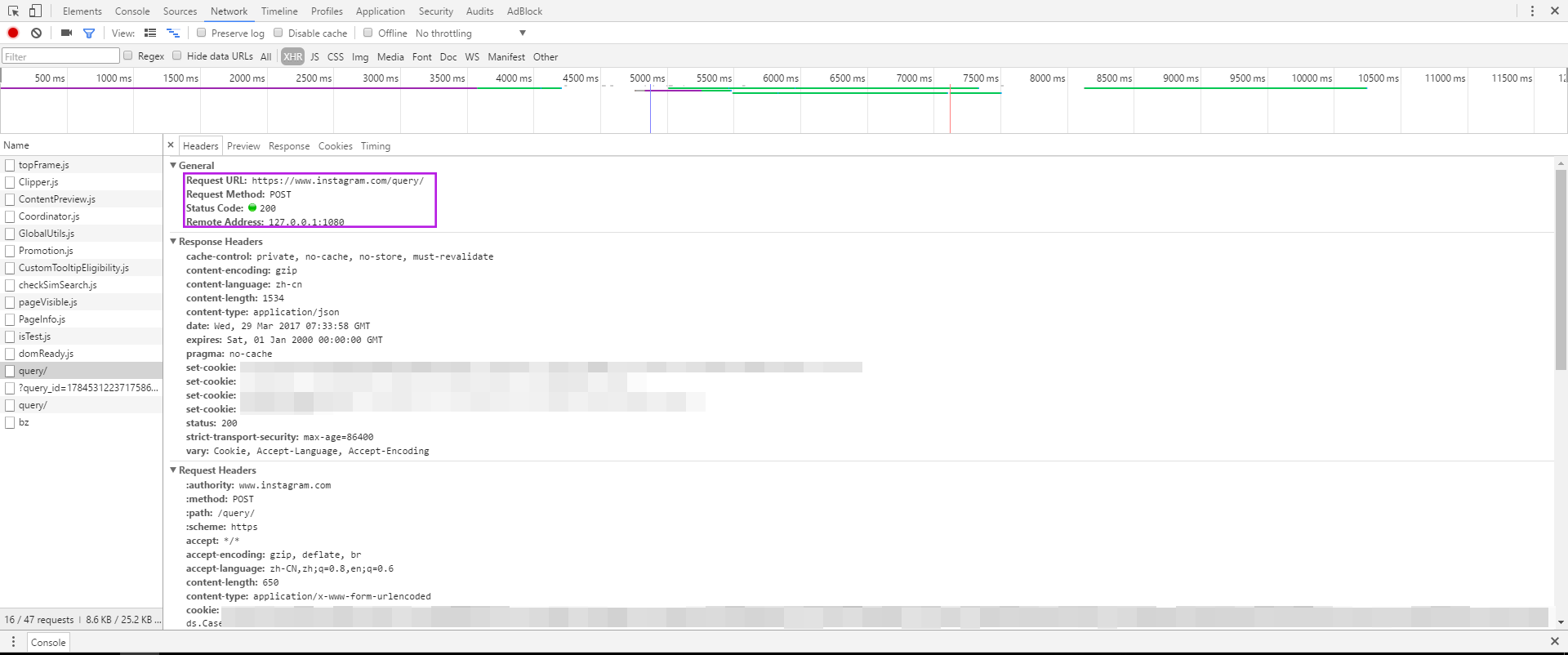
再看Request Heasers中,有个特殊的(其他网站不一定有的),x-csrftoken。这应该是关于CSRF(Cross-Site Request Forgery)跨站点伪造相关的设置???
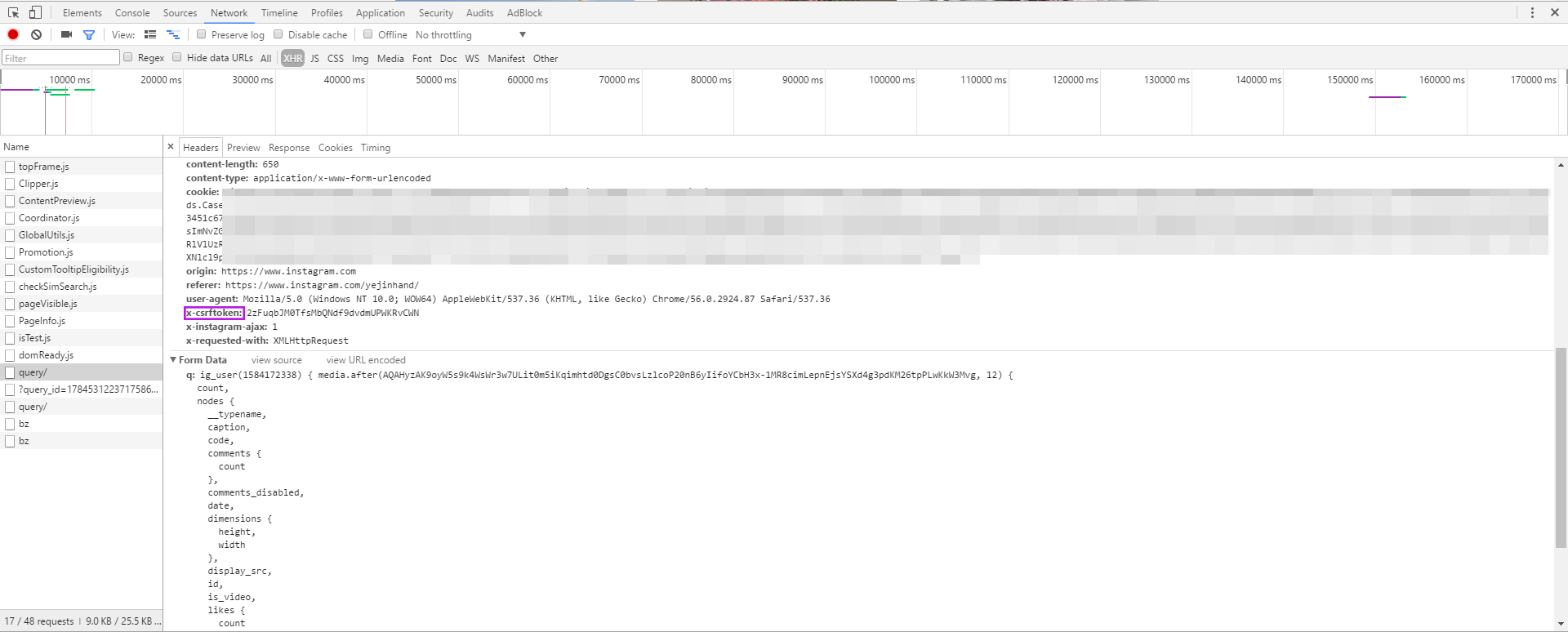
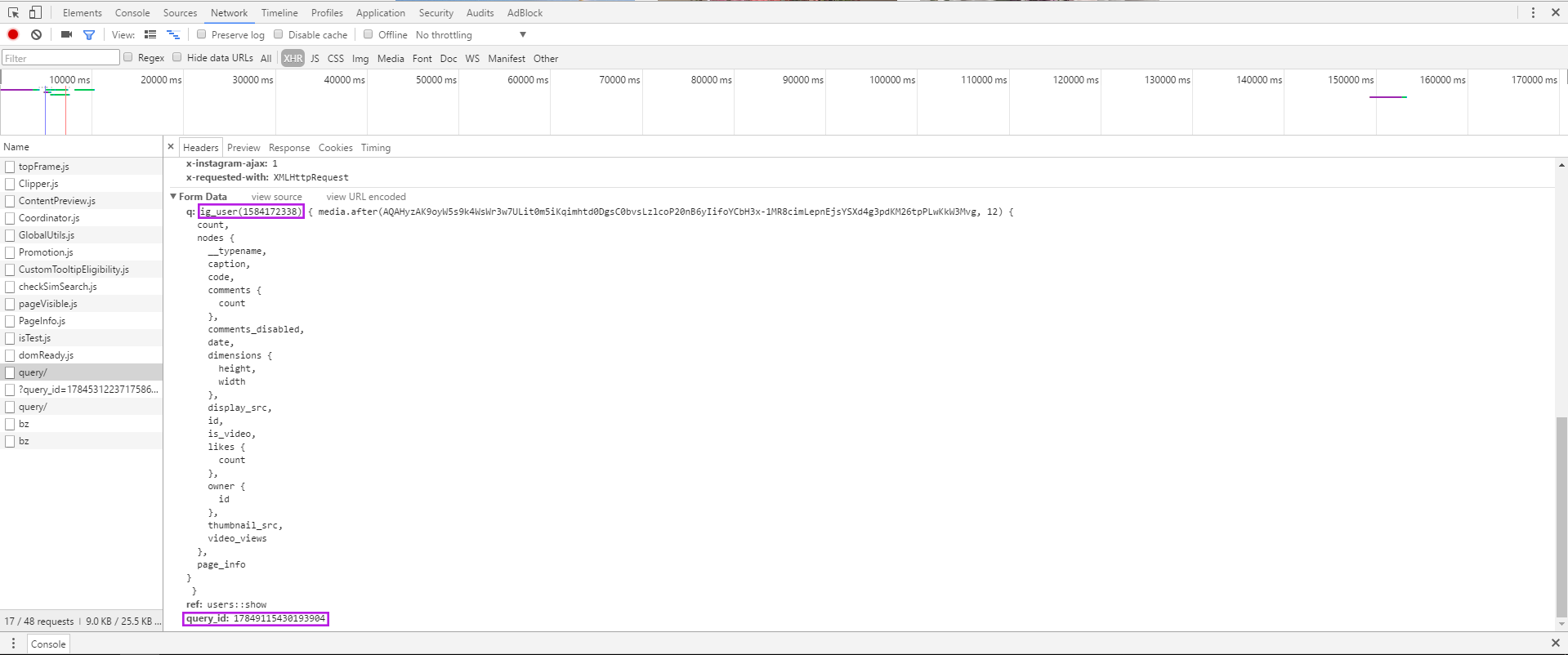
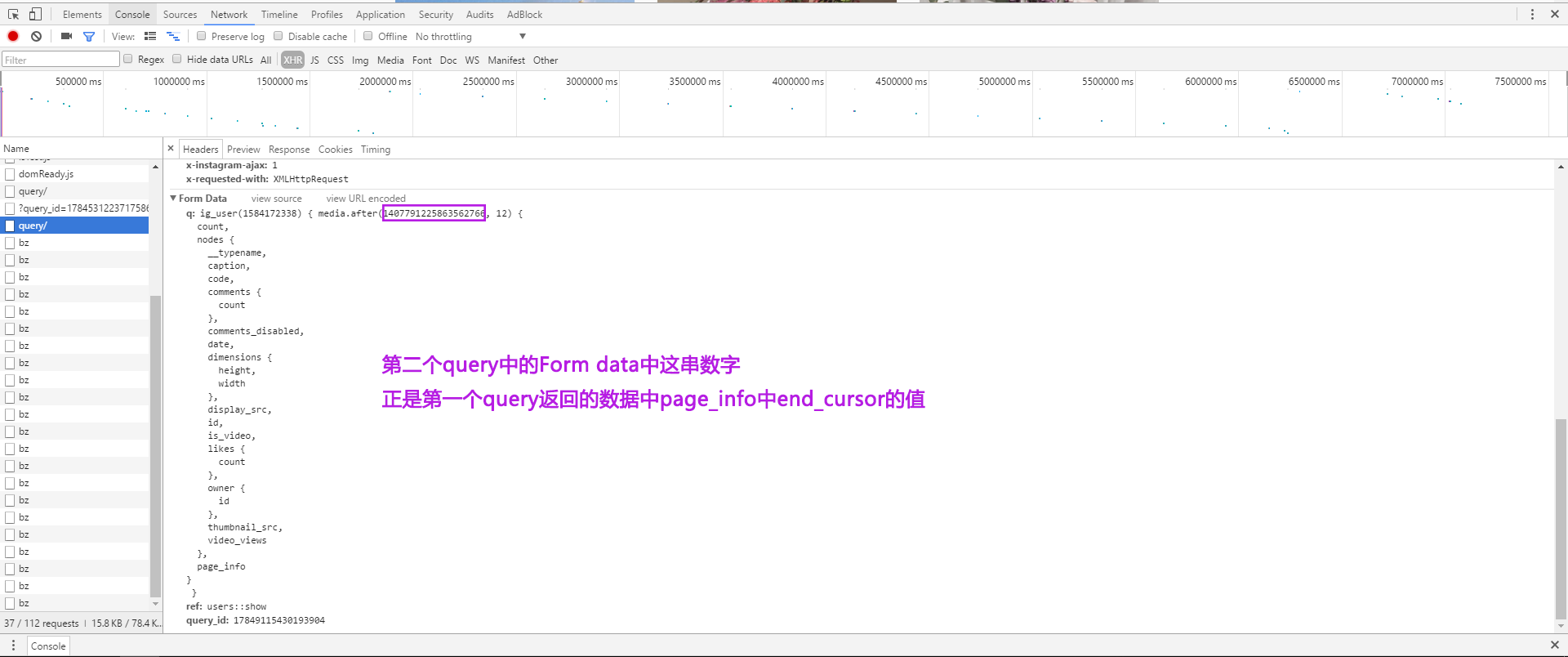
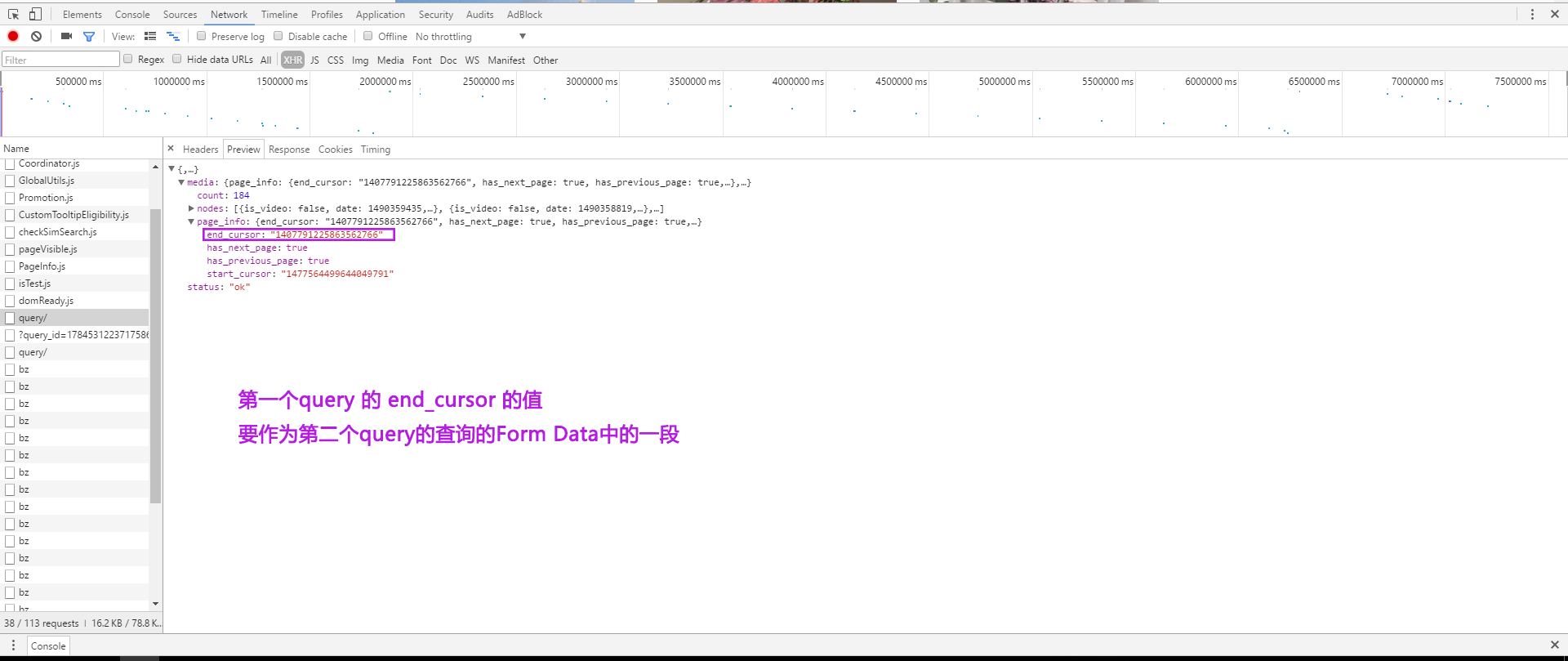
最后,还有一些Form Data。开始时不知道是做什么的。后来发现,加载更多数据,有一个新的query文件时,ig_user(1584172338)以及query_id:17849115430193904总是不变的。而第二个query中Form Data中的media.after(1407791225863562766, 12),1407791225863562766正是上一个query中返回数据的page_info中的end_cursor的值。所以根据这块儿信息可以循环去请求新的数据。
阶段3
开始code。
使用requests库发送HTTP请求,使用json库解析返回的响应json数据。
version1
需要翻个墙。所以发送请求时要加上proxies,注意写法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| import requests url = 'https://www.instagram.com/query/' proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080' } r = requests.post(url, proxies=proxies) print(r.status_code) print(r.text)
|
先不管登不登录的问题,被禁止访问,感觉由于没有模仿浏览器的行为?
version2
加上headers。尤其是user-agent。但还是仿照上面调试工具显示的Request Headers,把许多字段都加上了,唯一没有加的是cookie,因为感觉太多了。。。不知道直接copy行不行,就先没有加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| import requests url = 'https://www.instagram.com/query/' headers = { 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'content-length': '0', 'content-type': 'application/x-www-form-urlencoded', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'origin': 'https://www.instagram.com', 'referer': 'https://www.instagram.com/yejinhand/', 'x-csrftoken': '2zFuqbJM0TfsMbQNdf9dvdmUPWKRvCWN', 'x-instagram-ajax': '1', 'x-requested-with': 'XMLHttpRequest' } proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080' } r = requests.post(url, headers=headers, proxies=proxies) print(r.status_code) print(r.text)
|
headers中的这些东西开始时都不知道是咩。只知道user-agent是表示,发送请求的是一个浏览器。而且开始时以为因为referer是h ttps://www.instagram.com/yejinhand/,所以会返回孙艺珍的Instagram的主页而不是其他人的主页。这些知识在第3部分再记录。
当时出现这个问题,在网上查了好多,应该是要设置cookie。有的是专门再设置一个cookie,但在这里找到了一个方法,将cookie直接写到headers中。
version3
Stackoverflow上Martin Konecny是说将Curl “Cookie”粘贴到headers中,不了解curl。但是我是直接copy调试工具中的cookie字段,然后粘贴到代码中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| import requests url = 'https://www.instagram.com/query/' headers = { 'cookie': '从调试面板中直接粘贴过来', 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'content-length': '0', 'content-type': 'application/x-www-form-urlencoded', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'origin': 'https://www.instagram.com', 'referer': 'https://www.instagram.com/yejinhand/', 'x-csrftoken': '2zFuqbJM0TfsMbQNdf9dvdmUPWKRvCWN', 'x-instagram-ajax': '1', 'x-requested-with': 'XMLHttpRequest' } proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080' } r = requests.post(url, headers=headers, proxies=proxies) print(r.status_code) print(r.text)
|
这下没有被禁止!!!但是服务器未能理解请求。返回的信息是说无效的参数。就说明请求时应该传一些参数的。应该就是Form data中的内容。
version4
加上Form Data。
开始时不知道Form Data是干什么的,也不知道怎样发送这些Form Data。在Request的文档中找到了‘’更加复杂的 POST 请求‘’,其中有介绍:
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式:
1 2 3 4 5 6 7 8 9 10 11 12
| >>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.post("http://httpbin.org/post", data=payload) >>> print(r.text) { ... "form": { "key2": "value2", "key1": "value1" }, ... }
|
当时不知道Form Data并不是真正的表单数据,但翻译正好表单数据,感觉和这个介绍很类似。但是在调试面板中看到其Form Data那么麻烦,不知道怎样写。试了好几次才闹好。有三个字段:q、ref、query_id。其中q的值,ig_user()后是一个{},其中有media.after()以及另一个{},其中又有count、nodes、page_info,nodes中又有其他一些信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| import requests url = 'https://www.instagram.com/query/' headers = { 'cookie': '从调试面板中直接粘贴过来', 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'content-length': '0', 'content-type': 'application/x-www-form-urlencoded', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'origin': 'https://www.instagram.com', 'referer': 'https://www.instagram.com/yejinhand/', 'x-csrftoken': '2zFuqbJM0TfsMbQNdf9dvdmUPWKRvCWN', 'x-instagram-ajax': '1', 'x-requested-with': 'XMLHttpRequest' } proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080' } query_data = { 'q': 'ig_user(1584172338){media.after(1407791225863562766, 12){count,nodes{__typename,caption,code,comments{count},comments_disabled,date,dimensions{height,width},display_src,id,is_video,likes{count},owner{id},thumbnail_src,video_views},page_info}}', 'ref': 'users::show', 'query_id': '17849115430193904' } r = requests.post(url, data=query_data, headers=headers, proxies=proxies) print(r.status_code) print(r.text)
|
这样就成了!之后用json库解析的到的响应,就能得到自己所需的图片、视频url以及下一个请求的query_data了(将media.after后的数字替换为这一页的end_cursor)。
后来发现,在Form Data中可以只写自己想要的数据,比如这里只需要media中的page_info、nodes中的displa_src、is_video、以及node的code(查找视频的url是需要)。所以可以将query_data写成
1 2 3 4 5
| query_data = { 'q': 'ig_user(1584172338){media.after(1407791225863562766, 12){nodes{code, display_src, is_video}}, page_info}', 'ref': 'users::show', 'query_id': '17849115430193904' }
|
version5
其实写出version4之前,cookie处和query_data的内容始终写不对。而且一直以为是要登录后才可以请求到所有的数据。在网上找到说是request库中Session可以保存登录信息,但也不会写。。。直到找到了这个,功能很强,可以登录,可以根据用户、标签等进行爬虫等等。但我所需的只是其中很少的一部分,根据其登录模块,写了以下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62
| import requests import random import time import json login_url = 'https://www.instagram.com/accounts/login/ajax/' url = 'https://www.instagram.com/query/' get_url = 'https://www.instagram.com/' proxy = { "http": "http://127.0.0.1:1080", "https": "https://127.0.0.1:1080" } login_data = { 'username': '用户名', 'password': '密码' } s = requests.Session() s.cookies.update({'sessionid': '', 'mid': '', 'ig_pr': '1', 'ig_vw': '1920', 'csrftoken': '', 's_network': '', 'ds_user_id': ''}) s.headers.update({'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'en-US,en;q=0.8', 'Connection': 'keep-alive', 'Content-Length': '0', 'Host': 'www.instagram.com', 'Origin': 'https://www.instagram.com', 'Referer': 'https://www.instagram.com/', 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36,(KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36', 'X-Instagram-AJAX': '1', 'X-Requested-With': 'XMLHttpRequest', }) r = s.get(get_url) s.headers.update({'X-CSRFToken': r.cookies['csrftoken']}) time.sleep(4 * random.random()) login = s.post(login_url, data=login_data, proxies=proxy, allow_redirects=True) s.headers.update({'X-CSRFToken': login.cookies['csrftoken']}) time.sleep(5 * random.random()) query_data = { 'q': 'ig_user(1584172338){media.after(1407791225863562766, 12){count,nodes{__typename,caption,code,comments{count},comments_disabled,date,dimensions{height,width},display_src,id,is_video,likes{count},owner{id},thumbnail_src,video_views},page_info}}', 'ref': 'users::show', 'query_id': '17849115430193904' } r = s.post(url, data=query_data, proxies=proxy) print(r.status_code) print(r.text)
|
这样,应该是通过Seesion保存了登录的信息。但发现在初始化cookies时,就没有存什么东西,而在登录之后,只是根据返回的cookies中的csrftoken字段的值更新了发送请求headers中的x-csrftoken的值。所以将上边的初始更新cookies的代码删掉后也可以成功获取到所需json数据!!!
version6
同时,发现真正影响拒绝请求还是接受请求的地方在于请求的headers中的x-csrftoken的值和cookies中csrftoken字段要一致!!!所以version4的代码可以精简为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
| import requests url = 'https://www.instagram.com/query/' headers = { 'cookie': 'csrftoken=2zFuqbJM0TfsMbQNdf9dvdmUPWKRvCWN', 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'content-length': '0', 'content-type': 'application/x-www-form-urlencoded', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'origin': 'https://www.instagram.com', 'referer': 'https://www.instagram.com/yejinhand/', 'x-csrftoken': '2zFuqbJM0TfsMbQNdf9dvdmUPWKRvCWN', 'x-instagram-ajax': '1', 'x-requested-with': 'XMLHttpRequest' } proxies = { 'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080' } query_data = { 'q': 'ig_user(1584172338){media.after(1407791225863562766, 12){nodes{code, display_src, is_video}}, page_info}', 'ref': 'users::show', 'query_id': '17849115430193904' } r = requests.post(url, data=query_data, headers=headers, proxies=proxies) print(r.status_code) print(r.text)
|
而且试了试,将x-csrftoken改成任意的字符,只要保证cookies中的crsftoken字段和headers中crsftoken的字段一致就可以!!!也不用必须是多少个字符!!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| headers = { 'cookie': 'csrftoken=a', 'x-csrftoken': 'a' } headers = { 'cookie': 'csrftoken=asdfadsfs', 'x-csrftoken': 'asdfadsfs' } headers = { 'cookie': 'csrftoken=a', 'x-csrftoken': 'aa' }
|
但这是为什么???还没有闹清楚。
阶段4
图片的url都能找到了,但是上边请求的url返回的数据中并没有视频的url,如果是个视频的话,只是其中is_video字段的值是true。
找到一个视频,点击播放。还是同阶段1一样,打开调试工具。发现点击一个视频时,有个请求发出去了。其返回的数据中就有视频的url。
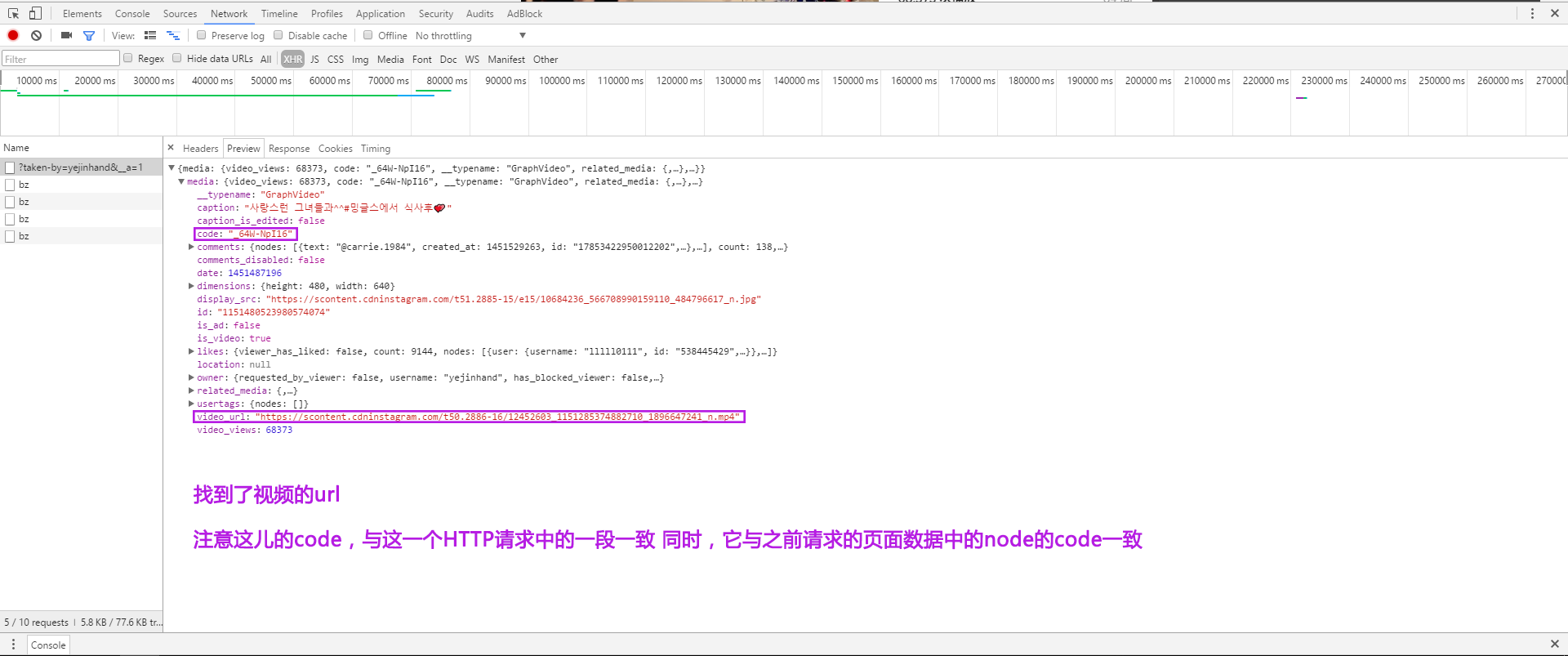
再OB其请求的headers。发现其中一段字符正是该node的code,与页面请求返回的数据中node的code一致。
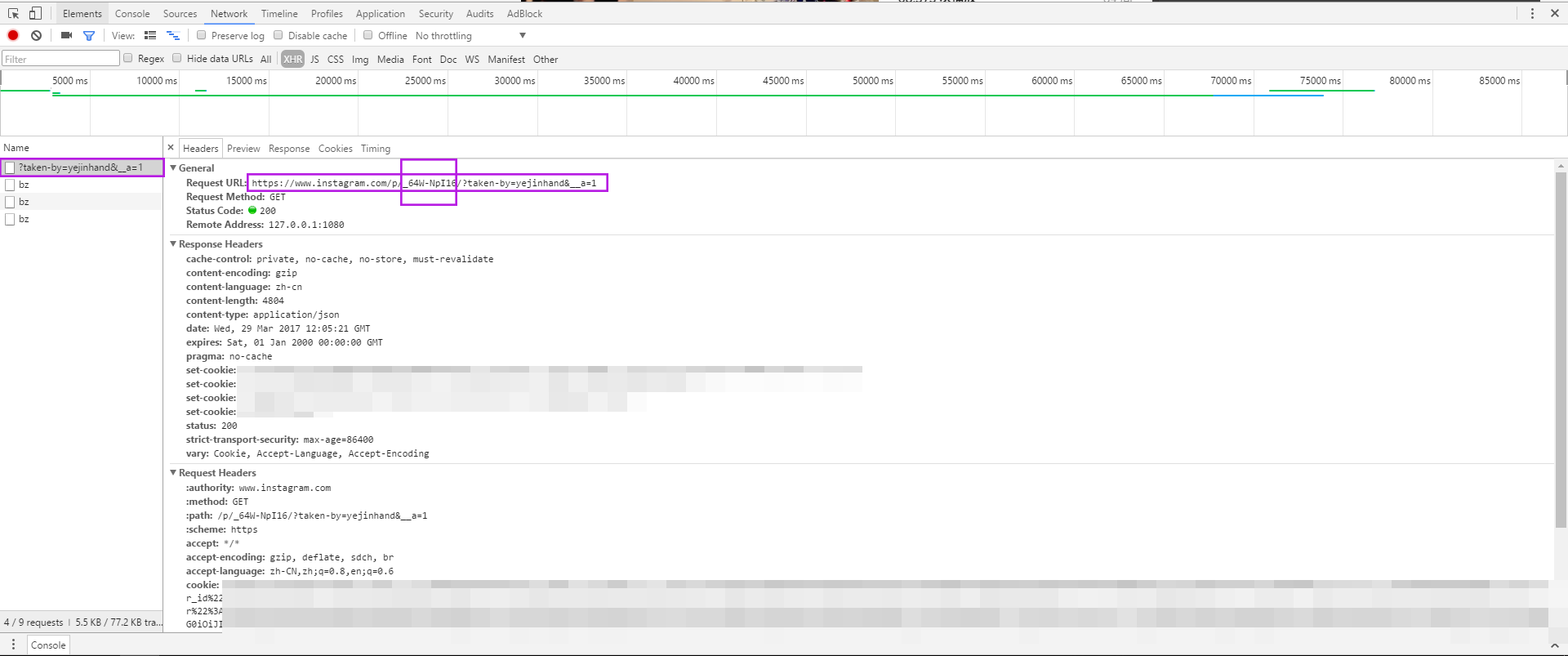
所以有了找图片以及视频url的思路。还是不断的发送h ttps://www.instagram.com/query/ 请求,根据上一次返回的数据中的end_cursor更新每一次请求时的Form Data,每次大概返回12个node信息,根据其中is_video字段,若是图片,就提取其url,完成任务。若是视频,就提取其code,根据code构造另一个HTTP请求(类似上图所示的请求),再在其返回数据中提取视频的url,完成任务。
阶段5
完成程序。模仿类似的爬虫,将爬到所有图片url和视频url存储到硬盘上的txt文件中。
先在硬盘上创建两个文件夹用来存放image.txt和video.txt;写了一个查找视频url的函数(就是根据video所在node的code构造一个HTTP请求,再解析其json数据响应,取到视频的url);之后设置爬虫所需的url、headers、proxies、form data;新建两个空列表,用来存储图片和视频的url;之后打开本地的image.txt和video.txt,将其中已有的先加入这两个空列表(主要是为下一次运行做准备,不要找的重复了。但现在想来是没有必要的,反正总把会某个用户主页上的所有资源都再请求一遍……不过可以保存住他/她删除了的图片或视频。也不对,已经删除了,url也就不能用了吧……);之后就是循环的去发送请求了,根据响应的page_info中的has_next_page来判断要不要跳出循环,在循环体内找到一个资源的url就加入相应的列表;最后把两个列表中的数据存储到硬盘上。
最后根据硬盘上的资源url去下载,写了两个Python脚本。(文件打开方式是wb,写入二进制)
一个是第一次下载images.txt和videos.txt中的链接。有可能很多条,中间可能发生崩溃,所以设置process_image和process_video来记录已经下载的个数;为了下一次只下载新增的url,设置了此次已下载的个数last_num。
另一个是下载新增的资源。新增的资源还是在imgages.txt和videos.txt中存着,并且是在最上 这里错了,爬取到资源url时,打开文件(images.txt和videos.txt)方式是w+,应该是r+,所以新的资源url是在最后。先读取上一次下载后的总个数,再根据此时imgages.txt和videos.txt中链接个数判断要下载哪些链接,完成后再更新last_num值。
还不太了解Python中的类、对象,所以就简单的写成了顺序执行的代码……而且为了保存下载进度,频繁的打开关闭文件,开销是不是很大??但想不出其他的解决办法了??还有一点,下载新的链接可以正确实现??
爬取链接的结果ig_syz.py:
第一次下载的结果download.py:
图片和视频:
运行下载新的链接脚本的结果download_new.py:
具体代码挂在GitHub上,点这里。
3. 基础知识
需要的一些基础知识有HTTP请求(尤其是其中的headers)、Ajax技术、XmlHttpRequest对象、CSRF(Cross-Site Request Forgery)、JSON数据。
这些内容在《JS高程》有一些。下一篇博客再记录吧。
4. 参考资料